
NL-Augmenter 🦎 → 🐍 A Framework for Task-Sensitive Natural Language Augmentation
Published:
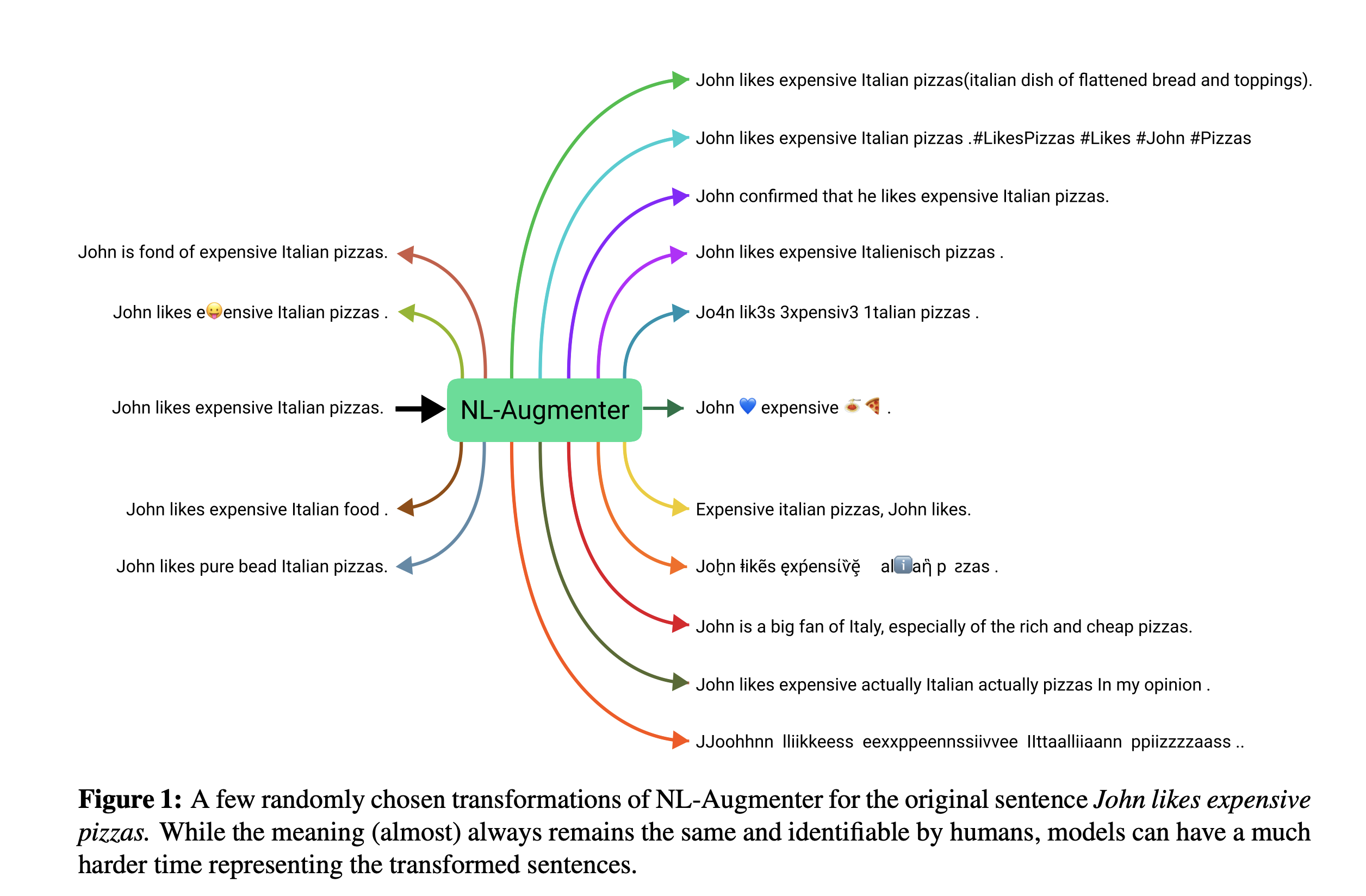
This paper introduces a new participative Python-based framework for natural language augmentation that enables the implementation of transformations (data alterations) and filters (data splits according to specific features). The framework’s current version includes 117 transformations and 23 filters that address a range of natural language problems.
My Contribution - Replace Spelling Perturbation 🦎 + ⌨️ → 🐍
I contributed replace spelling perturbation
This perturbation adds noise to all types of text sources (sentence, paragraph, etc.) using corpora of misspellings making common spelling errors.
What type of a transformation is this?
This transformation acts like a perturbation to test robustness. Few words picked at random are replaced with their common spelling errors if these words are in the corpus of mis-spell words. Generated transformations display high similarity to the source sentences i.e. the code outputs highly precise generations.
Data Curation
Dataset Source: https://www.dcs.bbk.ac.uk/~ROGER/corpora.html
A json file named spell_errors.json has been created by merging words from below files. Json file has actual word in lowercase as key and list of mis-spelt words of the key as value. The list of mis-spelt words has been created from all the files by taking union of words from below files when key word appears in multiple files.
| Sr No. | Dataset File | Description | Details |
|---|---|---|---|
| 1 | birkbeck.dat | 36,133 misspellings of 6,136 words | Amalgamation of errors taken from the native-speaker section (British or American writers) of the Birkbeck spelling error corpus. It includes the results of spelling tests and errors from free writing, taken mostly from school children, university students or adult literacy students. Most of them were originally handwritten. |
| 2 | holbrook-tagged.dat and holbrook-missp.dat | 1791 misspellings of 1200 target words | Derived from the passages from the book ‘English for the Rejected’ by David Holbrook, Cambridge University Press, 1964. They are extracts from the writings of secondary-school children, in their next-to-last year of schooling. |
| 3 | aspell.dat | 531 misspellings of 450 words | Derived from one assembled by Atkinson for testing the GNU Aspell spellchecker. This version is based closely on one used by Deorowicz and Ciura in a recent paper (“Correcting spelling errors by modelling their causes”) \cite{deorowicz2005correcting}. |
| 4 | wikipedia.dat | 2,455 misspellings of 1,922 | Misspellings made by Wikipedia editors. |
What are the limitations of this transformation?
The transformation’s outputs from corpus which is mostly based on hand-written text errors. Unlike a paraphraser, it is not capable of generating linguistically diverse text.
References
- Roger Mitton, A Corpus of Spelling Errors, https://www.dcs.bbk.ac.uk/~ROGER/corpora.html
@article{deorowicz2005correcting,
title={Correcting spelling errors by modelling their causes},
author={Deorowicz, Sebastian and Ciura, Marcin G},
journal={International journal of applied mathematics and computer science},
volume={15},
pages={275--285},
year={2005}
}
NL-Augmenter: A Framework for Task-Sensitive Natural Language Augmentation
— AK (@ak92501) December 7, 2021
abs: https://t.co/7O4qeAb0fy
github: https://t.co/AA6DiPBCHg
a new participatory Python-based NL augmentation framework which supports the creation of both transformations and filters pic.twitter.com/jUXOfT7mt3