
Abstract
Published:
In this project, we used Kaggle dataset of Fake news and downloaded real news from Guardian website. Most existing works have used supervised learning but given importance to the words used in the dataset. The approach may work well when the dataset is huge and covers a wide domain. Additionally, the algorithms are trained after the news has already been disseminated. In contrast, this research gives importance to content-based prediction based on language statistical features. A pattern in the language features can predict whether the news is fake or not. We extracted 43 features that include Parts of Speech and Sentiment Analysis Features. We implemented AdaBoost classifier; DecisionTreeClassifier; GaussianNB; KNeighborsClassifier; SGDClassifier; and SVC to predict whether a piece of particular news is fake or real.
Results show that AdaBoost Classifier with base estimator as Decision Tree of maximum depth $3$ and $175$ estimators performs best and provides accuracy close to 1. Features NN (noun, common, singular or mass); CD (numeral, cardinal); VBP (verb, present tense, not 3rd person singular); VBG(verb, present participle or gerund); positive (positive sentiment); NNP(noun, proper, singular); JJ(adjective or numeral, ordinal); IN(preposition or conjunction, subordinating); VBN(verb, past participle); and unique (unique words) were found top predictive features that provided accuracy of 0.85 and F-score of 0.87. In future work, we will implement this algorithm on other datasets.
Introduction
- What is Fake News?
- A piece of news, which is stylistically written as real news but is entirely or partially false Existing from a long time as propaganda but now due to social media and private news website/content providers
- Why?
- Well documented, unverified content - written to impact psychological beliefs
- Reason
- Information Separation - due to algorithms and preferences
Problem Statement
- Let $N = {n_1, n_2, n_3, … n_m}$ be a collection of $m$ news items and $L = {l_1, l_2, l_3, … l_m}$ be their corresponding labels of news items such that label li is either $1$ or $0$ depending on if the news item is fake or real.
- What is the label for $n_z \notin N$?
Previous approaches used dictionary-based approach
- Can we use language features to detect fake news?
- Clear intention to write fake news, and the content in fake news is written based on human psychology to influence social belief system
Features Extracted - 43
- 39 Parts of Speech Features
| Feature # | POS Tag | Description | Feature # | POS Tag | Description |
|---|---|---|---|---|---|
| 1 | $ | dollar | 2 | ”” | quotes |
| 3 | . | Dot | 4 | : | colon |
| 5 | CC | conjunction, coordinating | 6 | CD | numeral, cardinal |
| 7 | DT | determiner | 8 | EX | existential there |
| 9 | FW | foreign word | 10 | IN | preposition or conjunction, subordi- nating |
| 11 | JJ | adjective or numeral, ordinal | 12 | JJR | adjective, comparative |
| 13 | JJS | adjective, superlative | 14 | MD | modal auxiliary |
| 15 | NN | noun, common, singular or mass | 16 | NNP | noun, proper, singular |
| 17 | NNPS | noun, proper, plural | 18 | NNS | noun, common, plural |
| 19 | PDT | pre-determiner | 20 | POS | genitive marker |
| 21 | PRP | pronoun, personal | 22 | PRP$ | pronoun, possessive |
| 23 | RB | adverb | 24 | RBR | adverb, comparative |
| 25 | RBS | adverb, superlative | 26 | RP | particle |
| 27 | SYM | symbol | 28 | TO | “to” as preposition or innitive marker |
| 29 | UH | interjection | 30 | VB | verb, base form |
| 31 | VBD | verb, past tense | 32 | VBG | verb, present participle or gerund |
| 33 | VBN | verb, past participle | 34 | VBP | verb, present tense, not 3rd person singular |
| 35 | VBZ | verb, present tense, 3rd person sin- gular | 36 | WDT | WH-determiner |
| 37 | WP | WH-pronoun | 38 | WP$ | WH-pronoun, possessive |
| 39 | WRB | Wh-adverb |
- 3 Sentiment Analysis
- Positive Words, Negative Words, Neurtal Words
- Unique Words
Algorithms
- Ada Boost Classifier
- Decision Trees Classifier
- Gaussian Naive Bayes (GaussianNB)
- K-Nearest Neighbors (KNeighbors)
- Stochastic Gradient Descent Classifier (SGDC)
- Support Vector Machine
Results
- Initial Performance with 100% of training data using default parameters
| Algorithm | Test Accuracy | Test F-Score |
|---|---|---|
| AdaBoostClassier | 0.9989 | 0.9993 |
| DecisionTreeClassier | 0.9980 | 0.9983 |
| GaussianNB | 0.9902 | 0.9867 |
| KNeighborsClassier | 0.9747 | 0.9822 |
| SGDClassier | 0.9859 | 0.9851 |
| SVC | 0.9966 | 0.9968 |
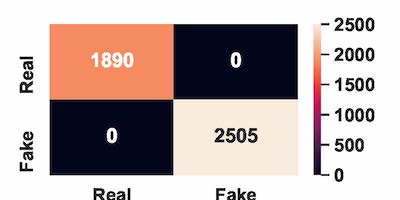 Confusion Matrix for Test Data
Confusion Matrix for Test Data
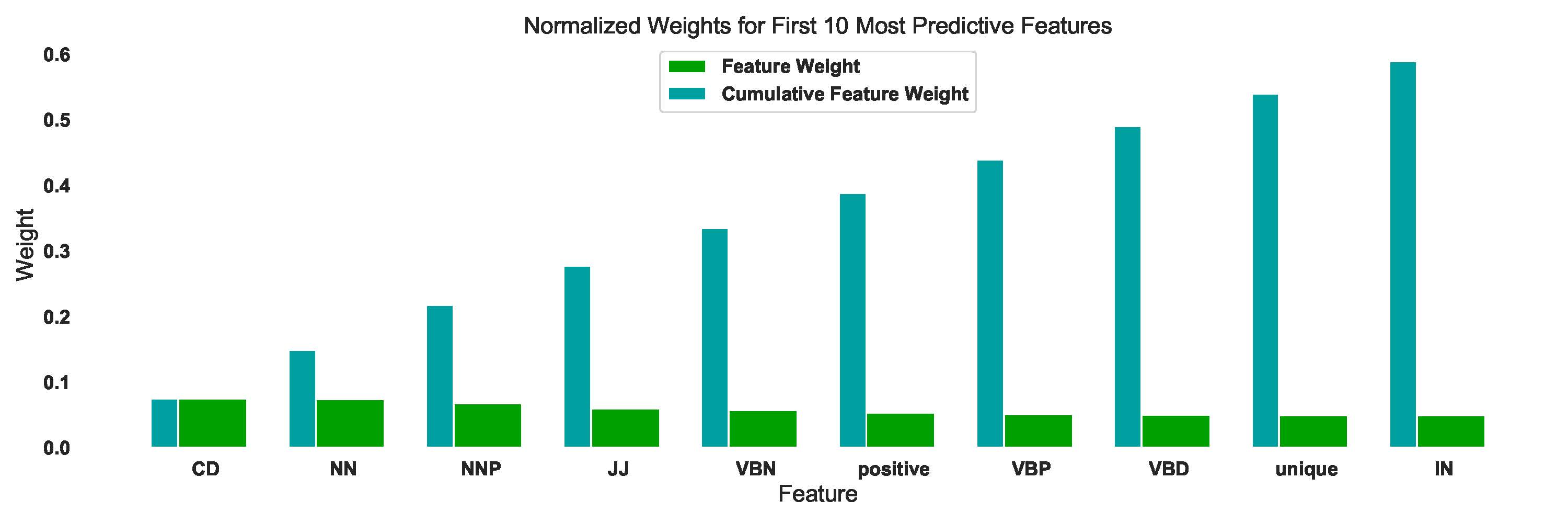 Important Language Features to predict Fake News
Important Language Features to predict Fake News
Citation
- Aneja N. and Aneja S. (2019). "Detecting Fake News with Machine Learning." International Conference on Deep Learning, Artificial Intelligence and Robotics, (ICDLAIR) 2019.