Introduction
Published:
Artificial intelligence (AI) is a thriving field with many practical applications and active research topics.
- automate routine labor, understand speech or images, make diagnoses in medicine and support basic scientific research.
In the early days of artificial intelligence, the field rapidly tackled and solved problems that are intellectually difficult for human beings but relatively straight-forward for computers—problems that can be described by a list of formal, mathematical rules. The true challenge to artificial intelligence proved to be solving the tasks that are easy for people to perform but hard for people to describe formally—problems that we solve intuitively, that feel automatic, like recognizing spoken words or faces in images
allow computers to learn from experience and understand the world in terms of a hierarchy of concepts, with each concept defined through its relation to simpler concepts.
By gathering knowledge from experience, this approach avoids the need for human operators to formally specify all the knowledge that the computer needs.
The hierarchy of concepts enables the computer to learn complicated concepts by building them out of simpler ones. If we draw a graph showing how these concepts are built on top of each other, the graph is deep, with many layers. For this reason, we call this approach to AI deep learning.
Many of the early successes of AI took place in relatively sterile and formal environments and did not require computers to have much knowledge about the world. For example, IBM’s Deep Blue chess-playing system defeated world champion Garry Kasparov in 1997 (Hsu, 2002). Chess is of course a very simple world, containing only sixty-four locations and thirty-two pieces that can move in only rigidly circumscribed ways. Devising a successful chess strategy is a tremendous accomplishment, but the challenge is not due to the difficulty of describing the set of chess pieces and allowable moves to the computer. Chess can be completely described by a very brief list of completely formal rules, easily provided ahead of time by the programmer.
Ironically, abstract and formal tasks that are among the most difficult mental undertakings for a human being are among the easiest for a computer. Computers have long been able to defeat even the best human chess player but only recently have begun matching some of the abilities of average human beings to recognize objects or speech.
A person’s everyday life requires an immense amount of knowledge about the world. Much of this knowledge is subjective and intuitive, and therefore difficult to articulate in a formal way. Computers need to capture this same knowledge in order to behave in an intelligent way.
One of the key challenges in artificial intelligence is how to get this informal knowledge into a computer Several artificial intelligence projects have sought to hard-code knowledge about the world in formal languages.
A computer can reason automatically about statements in these formal languages using logical inference rules. This is known as the ==knowledge base approach== to artificial intelligence. None of these projects hasled to a major success.
One of the most famous such projects is Cyc (Lenat andGuha, 1989). Cyc is an inference engine and a database of statements in a language called CycL. These statements are entered by a staff of human supervisors. It is an unwieldy process. People struggle to devise formal rules with enough complexity to accurately describe the world. For example, Cyc failed to understand a story about a person named Fred shaving in the morning (Linde, 1992). Its inference engine detected an inconsistency in the story: it knew that people do not have electrical parts, but because Fred was holding an electric razor, it believed the entity “FredWhileShaving” contained electrical parts. It therefore asked whether Fred was still a person while he was shaving.
The difficulties faced by systems relying on hard-coded knowledge suggest that AI systems need the ability to acquire their own knowledge, by extracting patterns from raw data. This capability is known as ==machine learning==.
The introduction of machine learning enabled computers to tackle problems involving knowledge of the real world and make decisions that appear subjective. A simple machine learning algorithm called logistic regression can determine whether to recommend cesarean delivery (Mor-Yosef et al., 1990). A simple machine learning algorithm called naive Bayes can separate legitimate e-mail from spam e-mail.**
The performance of these simple machine learning algorithms depends heavily on the ==representation== of the data they are given. For example, when logistic regression is used to recommend cesarean delivery, the AI system does not examine the patient directly. Instead, the doctor tells the system several pieces of relevant information, such as the presence or absence of a uterine scar. Each piece of information included in the representation of the patient is known as a ==feature==.
Logistic regression learns how each of these features of the patient correlates with various outcomes. However, it cannot influence how features are defined in any way. If logistic regression were given an MRI scan of the patient, rather than the doctor’s formalized report, it would not be able to make useful predictions.
Individual pixels in an MRI scan have negligible correlation with any complications that might occur during delivery.
This dependence on representations is a general phenomenon that appears throughout computer science and even daily life.
In computer science, operations such as searching a collection of data can proceed exponentially faster if the collection is structured and indexed intelligently. People can easily perform arithmetic on Arabic numerals but find arithmetic on Roman numerals much more time consuming. It is not surprising that the choice of representation has an enormous effect on the performance of machine learning algorithms. For a simple visual example:
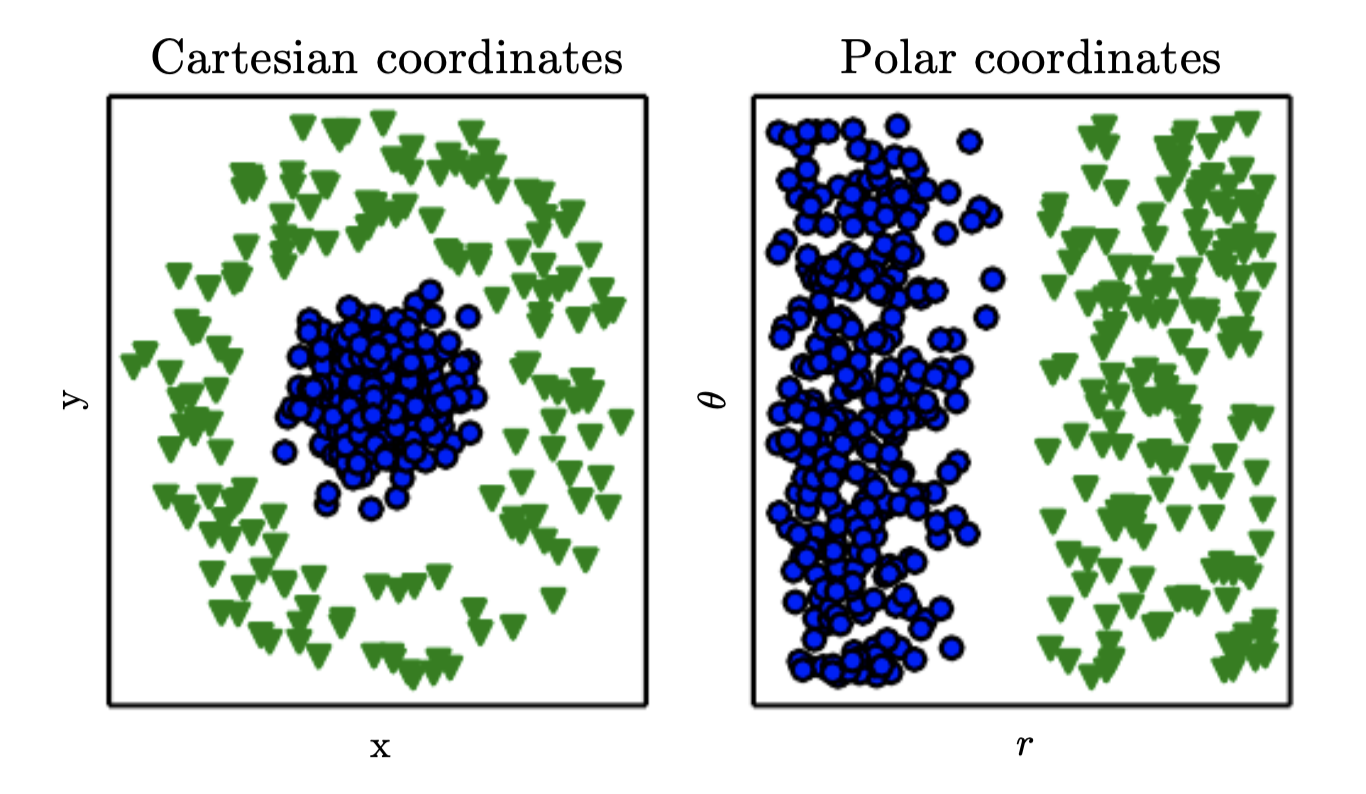
Many artificial intelligence tasks can be solved by designing the right set of features to extract for that task, then providing these features to a simple machine learning algorithm.
For example, a useful feature for speaker identification from sound is an estimate of the size of the speaker’s vocal tract. This feature gives a strong clue as to whether the speaker is a man, woman, or child.
For many tasks, however, it is difficult to know what features should be extracted. For example, suppose that we would like to write a program to detect cars in photographs. We know that cars have wheels, so we might like to use the presence of a wheel as a feature. Unfortunately, it is difficult to describe exactly what a wheel looks like in terms of pixel values. A wheel has a simple geometric shape, but its image may be complicated by shadows falling on the wheel, the sun glaring off the metal parts of the wheel, the fender of the car or an object in the foreground obscuring part of the wheel, and so on.
One solution to this problem is to use machine learning to discover not only the mapping from representation to output but also the representation itself. This approach is known as ==representation learning==.
Learned representations often result in much better performance than can be obtained with hand-designed representations. They also enable AI systems to rapidly adapt to new tasks, with minimal human intervention. A representation learning algorithm can discover a good set of features for a simple task in minutes, or for a complex task in hours to months.
Manually designing features for a complex task requires a great deal of human time and effort; it can take decades for an entire community of researchers.
The quintessential example of a representation learning algorithm is the ==autoencoder==. An autoencoder is the combination of an encoder function, which converts the input data into a different representation, and a decoder function, which converts the new representation back into the original format.
Autoencoders are trained to preserve as much information as possible when an input is run through the encoder and then the decoder, but they are also trained to make the new representation have various nice properties. Different kinds of autoencoders aim to achieve different kinds of properties.
When designing features or algorithms for learning features, our goal is usually to separate the ==factors of variation that explain the observed data==. In this context, we use the word “factors” simply to refer to separate sources of influence; the factors are usually not combined by multiplication.
Such factors are often not quantities that are directly observed. Instead, they may exist as either unobserved objects or unobserved forces in the physical world that affect observable quantities.
They may also exist as constructs in the human mind that provide useful simplifying explanations or inferred causes of the observed data. They can be thought of as concepts or abstractions that help us make sense of the rich variability in the data.
When analyzing a speech recording, the factors of variation include the speaker’s age, their gender, their accent and the words they are speaking. When analyzing an image of a car, the factors of variation include the position of the car, its color, and the angle and brightness of the sun.
A major source of difficulty in many real-world artificial intelligence applications
is that many of the factors of variation influence every single piece of data we are
able to observe. The individual pixels in an image of a red car might be very close
to black at night. The shape of the car’s silhouette depends on the viewing angle.
Most applications require us to disentangle the factors of variation and discard the
ones that we do not care about.
Of course, it can be very difficult to extract such high-level, abstract features
from raw data. Many of these factors of variation, such as a speaker’s accent,
can be identified only using sophisticated, nearly human-level understanding of
the data. When it is nearly as difficult to obtain a representation as to solve the
original problem, representation learning does not, at first glance, seem to help us.


