ANOVA
Published:
This post explains ANOVA.
| ![]() |
|  | | ———————————————————— | ———————————————————— |
| | ———————————————————— | ———————————————————— |
Comparing Samples
| Product A | Product B | Product C |
|---|---|---|
| 12 | 40 | 65 |
| 15 | 45 | 45 |
| 10 | 50 | 30 |
| 14 | 60 | 40 |
- Which of the products have significantly different prices
- Product A and Product B
- Product A and Product C
- Product B and Product C
- No significant difference
- How many t-tests would we need to compare for 4 samples A, B, C, D
- 6 (AB, AC, AD, BC, BD, AD)
- $\binom{n}{2} = \frac{n!}{2!(n-2)!}$
$tStatistic = \frac{\bar{X_1}-\bar{X_2}}{\sqrt{\frac{S_1^2}{n_1}+\frac{S_2^2}{n_2}}}$
Compare three or more samples = $\frac{distance/variability~between~means}{error}$
To compare three or more samples
- Find the average squared deviation of each sample mean from the total mean
- like std
- Total Mean or Grand Mean $\bar{X_G}$
- Samples sizes equal
- Mean of all Means
- $\bar{X_G} = \text{Mean of sample means} = \frac{\bar{X_1} + \bar{X_2}+…+\bar{X_n}}{n}$
- Compute Mean of all values
- $\bar{X_G} = \frac{X_1 + X_2+…+X_N}{N}$
- Mean of all Means
- If not equal
- Compute Mean of all values
- $\bar{X_G} = \frac{X_1 + X_2+…+X_N}{N}$
- Compute Mean of all values
- Find the average squared deviation of each sample mean from the total mean
Between-group Variability
- Conclusions from the deviation of each sample mean from the mean of means
- Smaller the distance between sample means (mean of groups are close to each other)
- less likely population means will differ significantly
- Greater the distance between sample means (mean of groups are far from each other)
- more likely population means will differ significantly
- Smaller the distance between sample means (mean of groups are close to each other)
Within-group Variability
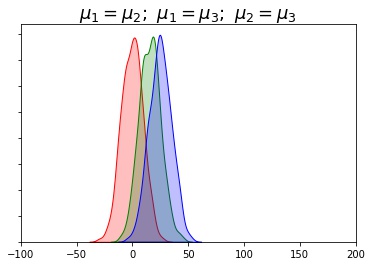
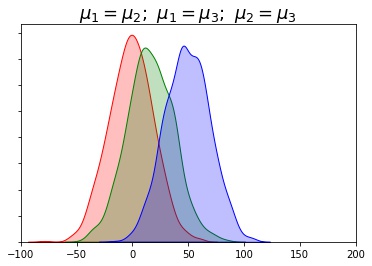
In which situation are the means significantly different
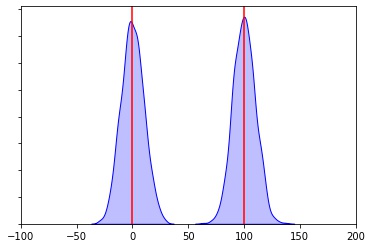
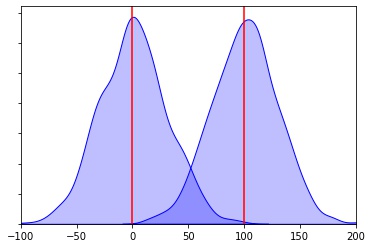
Less Variablity More Variablity The smaller the variability of each individual sample (chances are no overlap)
- the more likely population means will differ significantly
Greater the variability of each individual sample (since chances are for overlap)
- the less likely population means will differ significantly
ANalysis Of VAriance (ANOVA)
- One Test to compare $n$ means
- One-way ANOVA
- One Independent Variable
- Two-way ANOVA
- Two Independent Variable
One-way ANOVA
- $H_0: \mu_1 = \mu_2 = \mu_3$
- $H_A:$ At least one pair of samples is significantly different
- $F = \frac{between-group~variability}{within-group~variability}$
- If we get small statistic
- Within-group > Between-group
- means are not significantly different from each other
- Fail to reject the Null
- Within-group > Between-group
- If we get large statistic
- Between-group > Within-group
- means are significantly different from each other
- Reject Null
- If we get small statistic
- Higher Within-group variability is in favour of Null Hypothesis
- Higher Between-group variability is in favor of Alternate Hypothesis
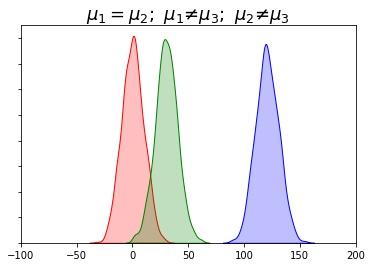 | 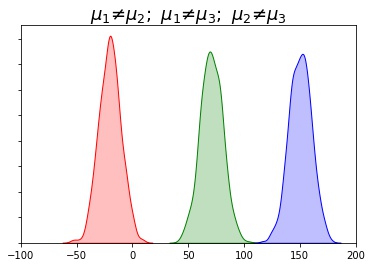 |
|---|---|
 |  |
ANOVA
- Between-group variability $ = \frac{n\Sigma(\bar{X_k}-\bar{X_G})^2}{k-1} $
- Within-group Variability $ = \frac{\Sigma(X_i-\bar{X_k})^2}{N-k} $, where $N$ is the total number of values from all samples and $k$ the number of Samples
- $F = \frac{\frac{n\Sigma(\bar{X_k}-\bar{X_G})^2}{k-1}}{\frac{\Sigma(X_i-\bar{X_k})^2}{N-k}} = \frac{\frac{SS_{betweeb}}{df_{between}}}{\frac{SS_{within}}{df_{within}}} = \frac{MS_{between}}{MS_{within}}$
- SS - Sum of Squared
- MS - Mean Squared
- $df_{total} = df_{between} + df_{within} = N - 1$
- $SS_{total} = \Sigma(x_i-\bar{X_G})^2 = SS_{between} + SS_{within}$
- $F$-statistic is never negative
- not symmatrical
- positively skewed
- Peakes at 1 since if no difference between population means then between-group and within group will be same
- Always No Direction $\ne$
- Critical region on right side only
Example One-way ANOVA
Same sample size
- Is there significant differences in prices of items from three brands based on data of prices of some random shirts
- [15, 12, 14, 11]
- [39, 45, 48, 60]
- [65, 45, 32, 38]
Hypothesis
- $H_0: \mu_1 = \mu_2 = \mu_3$
- $H_A:$ At least one pair of samples is significantly different
- Samples
brand1 = [15, 12, 14, 11]
brand2 = [39, 45, 48, 60]
brand3 = [65, 45, 32, 38]
- Means
- $\bar{X_1} = 13;~ \bar{X_2} = 48;~ \bar{X_3} = 45$
- $\bar{X_G} = \frac{13 + 48 + 45}{3} = 35.33$ (equal size)
- $ \bar{X_G} = \frac{15+12+14+11+39+45+48+60+65+45+32+38}{12} = 35.33$ (if unequal)
- SS_Between
- $ n \Sigma (\bar{X}_k - \bar{X}_G)^2 $
- $SS_{between} = 4 * [ (13-35.33)^2 + (48-35.33)^2 + (45-35.33)^2 ] = 3010.67$
- df_between
- $ df_{between} = k - 1 = 2 $; k is the number of groups
- SS_Within
- $ \Sigma (X_i - \bar{X}_k)^2 $
- $ SS_{within}(1) = (15-13)^2 + (12-13)^2 + (14-13)^2 + (11-13)^2 $
- $ SS_{within}(2) = (39-48)^2 + (45-48)^2 + (48-48)^2 + (60-48)^2$
- $ SS_{within}(3) = (65-45)^2 + (45-45)^2 + (32-45)^2 + (38-45)^2 $
- $ SS_{within} = SS_{within}(1) + SS_{within}(2) + SS_{within}(3) $
- $ SS_{within} = 862.00 $
- df_within
- $ df_{within} = N - k = 12 - 3 = 9 $
- MS_between
- $MS_{between} = \frac{SS_{between}}{df_{between}} = \frac{3010.67}{2} = 1505.33 $
- MS_within
- $MS_{within} = \frac{SS_{within}}{df_{within}} = \frac{862}{9} = 95.78 $
- Fstatistic
- $ Fstatistic = \frac{MS_{between}}{MS_{within}} = \frac{1505.33}{95.78} = 15.72 $
- Tables
- http://www.socr.ucla.edu/Applets.dir/F_Table.html
- https://naneja.github.io/files/statistics/tables.pdf
- When referencing the F distribution
- numerator degrees of freedom are always given first, as switching the order of degrees of freedom changes the distribution
- F(Numerator, Denominator)
- $df_{numerator} = column = 2$
- $df_{denominator} = row = 9 $
- $ F(.05, 2, 9)_{critical} = 4.2565 $
- Since $F_{statistic} = 15.72 > F_{critical} = 4.2665 $
- Reject Null
- F-table doesn’t give p-value
Different sample size
- Is there significant differences in prices of items from three brands based on data of prices of some random shirts:
- Brand 1: [15, 12, 14]
- Brand 2: [39, 45, 48, 60]
- Brand 3: [65, 45, 32]
- Use α = 1% to test if there is a significant difference. Show all of the computations and reasoning.
- Answers
- (i) Write the Hypothesis Test:
- $H0: \mu1 = \mu2 = \mu3$
- $Ha:$ not all three population means are equal or
- $Ha:$ At least one pair of samples is significantly different
- (ii) What is the value of Sum of Squared between (SS_between)
- Ans: 2435.167
- $n = [3, 4, 3]; \bar{X} = [13.67, 48, 47.33]$
- $\bar{X}_G = \frac{15 + 12 + 14 + 39 + 45 + 48 + 60 + 65 + 45 + 32}{10} = 37.5$
- $SS_{\text{between}} = 3(13.67-37.5)^2 + 4(48-37.5)^2 + 3*(47.33-37.5)^2$
- $SS_{\text{between}} = 2435.167$
- Ans: 2435.167
- (iii) What is the value of the degree of freedom between (df_between)
- Ans: $k-1 = 2$
- (iv) What is the value of Mean Squared between (MS_between)
- Ans: $ MS_{between} = \frac{SS_{between}}{df_{between}} = \frac{2435.167}{2}=1217.583$
- (v) What is the value of Sum of Squared within (SS_within)
- $SS_{within}1 = (15-13.67)^2 + (12-13.67)^2 + (14-13.67)^2 = 4.67$
- $SS_{within}2 = (39-48)^2 + (45-48)^2 + (48-48)^2 + (60-48)^2 = 234$
- $SS_{within}3 = (65-37.5)^2 + (45-37.5)^2 + (32-37.5)^2 = 552.67$
- $SS_{within} = SS_{within}1 + SS_{within}2 + SS_{within}3$
- $SS_{within} = 4.67 + 234 + 552.67 = 791.33 $
- (vi) What is the value of degree of freedom within (df_within)
- Ans: $ df_{within} = N-k = (3+4+3) - 3 = 7$
- (vii) What is the value of Mean Squared within (MS_within)
- Ans: $ MS_{within} = \frac{SS_{within}}{df_{within}} = \frac{791.33}{7} = 113.048$
- (viii) What is the value of Fstatistic
- Ans: $Fstatistic = \frac{MS_{between}}{MS_{within}} = \frac{1217.583}{113.048} = 10.771 $
- (ix) What is the value of Fcritical
- $Nr = df_{between} = 2; Dr = df_{within} = 7$
- $Col = 2; Row = 9 => F(0.01, 2, 9) = 9.547$
- (x) Do you reject the Null Hypothesis or Fail to Reject the Null. Also write the interpretation of rejecting the null or fail to reject the null.
- Ans: $Reject$ Null in favor of Alternate
- At least one pair of samples is significantly different
- (i) Write the Hypothesis Test:
Two-way ANOVA
- The only difference between one-way and two-way ANOVA is the number of independent variables. A one-way ANOVA has one independent variable, while a two-way ANOVA has two.
- used to determine whether or not there is a statistically significant difference between the means of three or more independent groups that have been split on two factors.
- The purpose of a two-way ANOVA is to determine how two factors impact a response variable, and to determine whether or not there is an interaction between the two factors on the response variable.
- For example, suppose a botanist wants to explore how sunlight exposure and watering frequency affect plant growth.
- She plants 30 seeds and lets them grow for two months under different conditions for sunlight exposure and watering frequency. After two months, she records the height of each plant.
- Response variable
- plant growth
- Factors
- sunlight exposure, watering frequency
- Questions
- Does sunlight exposure affect plant growth?
- Does watering frequency affect plant growth?
- Is there an interaction effect between sunlight exposure and watering frequency? (e.g. the effect that sunlight exposure has on the plants is dependent on watering frequency)
- Two-Way ANOVA Assumptions
Normality – The response variable is approximately normally distributed for each group.
Equal Variances – The variances for each group should be roughly equal.
Independence – The observations in each group are independent of each other and the observations within groups were obtained by a random sample.
Example
water = c('daily', 'daily', 'daily', 'daily', 'daily',
'daily', 'daily', 'daily', 'daily', 'daily',
'daily', 'daily', 'daily', 'daily', 'daily',
'weekly', 'weekly', 'weekly', 'weekly', 'weekly',
'weekly', 'weekly', 'weekly', 'weekly', 'weekly',
'weekly', 'weekly', 'weekly', 'weekly', 'weekly')
sun = c('low', 'low', 'low', 'low', 'low',
'med', 'med', 'med', 'med', 'med',
'high', 'high', 'high', 'high', 'high',
'low', 'low', 'low', 'low', 'low',
'med', 'med', 'med', 'med', 'med',
'high', 'high', 'high', 'high', 'high')
height = c(6, 6, 6, 5, 6, 5, 5, 6, 4, 5,
6, 6, 7, 8, 7, 3, 4, 4, 4, 5,
4, 4, 4, 4, 4, 5, 6, 6, 7, 8)
#create data frame
data <- data.frame(water = water,
sun = sun,
height = height)
print(data)
model <- aov(height ~ water * sun, data = data)
summary(model)
water = ['daily', 'daily', 'daily', 'daily', 'daily',
'daily', 'daily', 'daily', 'daily', 'daily',
'daily', 'daily', 'daily', 'daily', 'daily',
'weekly', 'weekly', 'weekly', 'weekly', 'weekly',
'weekly', 'weekly', 'weekly', 'weekly', 'weekly',
'weekly', 'weekly', 'weekly', 'weekly', 'weekly']
sun = ['low', 'low', 'low', 'low', 'low',
'med', 'med', 'med', 'med', 'med',
'high', 'high', 'high', 'high', 'high',
'low', 'low', 'low', 'low', 'low',
'med', 'med', 'med', 'med', 'med',
'high', 'high', 'high', 'high', 'high']
height = [6, 6, 6, 5, 6, 5, 5, 6, 4, 5,
6, 6, 7, 8, 7, 3, 4, 4, 4, 5,
4, 4, 4, 4, 4, 5, 6, 6, 7, 8]
data = {'water': water,'sun': sun,'height': height}
df = pd.DataFrame(data)
print(df.head(3))
# !pip3 install statsmodels
import statsmodels.api as sm
from statsmodels.formula.api import ols
#perform two-way ANOVA
model = ols('height ~ C(water) + C(sun) + C(water):C(sun)', data=df).fit()
sm.stats.anova_lm(model, typ=2)
| sum_sq | df | F | PR(>F) | ||
|---|---|---|---|---|---|
| C(water) | 8.533333 | 1.0 | 16.0000 | 0.000527 | *** |
| C(sun) | 24.866667 | 2.0 | 23.3125 | 0.000002 | *** |
| C(water):C(sun) | 2.466667 | 2.0 | 2.3125 | 0.120667 | |
| Residual | 12.800000 | 24.0 | NaN | NaN |
- Interpret the results.
- We can see the following p-values for each of the factors in the table:
- water: p-value = .000527
- sun: p-value = .0000002
- water*sun: p-value = .120667
- Since the p-values for water and sun are both less than .05, this means that both factors have a statistically significant effect on plant height.
- since the p-value for the interaction effect (.120667) is not less than .05, this tells us that there is no significant interaction effect between sunlight exposure and watering frequency.
- We can see the following p-values for each of the factors in the table:


